后端流程图
点击某一项 查看更多详情,或查看完整的索引。
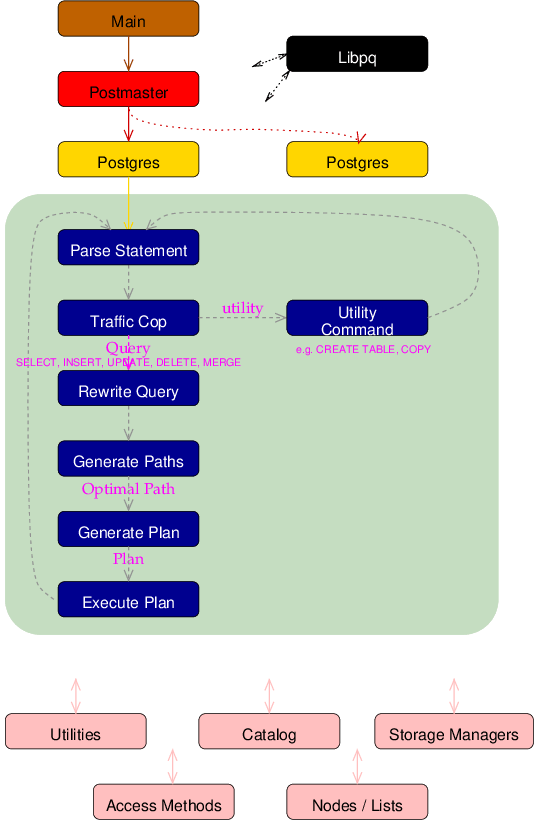
查询通过 TCP/IP 或 Unix Domain 套接字的传入数据包到达后端。它被加载到一个字符串中,然后传递给解析器(parser),在那里词法扫描器 scan.l 将查询分解成标记(词语)。解析器使用 gram.y 和标记来识别查询类型,并加载适当的特定于查询的结构,例如 CreateStmt 或 SelectStmt。
然后,语句被识别为复杂语句(SELECT / INSERT / UPDATE / DELETE)或简单语句,例如 CREATE ROLE, ANALYZE, 等。不需要执行器的简单实用命令由 命令(commands)模块中的特定于语句的函数处理。复杂语句需要更多的处理。
解析器接收复杂查询,并创建一个包含复杂查询所使用的所有元素的Query结构。Query.jointree 保存FROM和WHERE子句,它由 transformFromClause() 和 transformWhereClause() 填充。查询中引用的每个表都由一个 RangeTblEntry 表示,它们被链接在一起形成查询的范围表(range table),该表由 transformFromClause() 生成。Query.rtable 保存查询的范围表。
某些查询,如SELECT,返回数据列。其他查询,如INSERT和UPDATE,指定被查询修改的列。这些列引用被转换为 TargetEntry 条目,它们被链接在一起构成查询的目标列表(target list)。目标列表存储在 Query.targetList 中,它由 transformTargetList() 生成。
其他查询元素,例如聚合函数(SUM())、GROUP BY 和ORDER BY 也存储在各自的 Query 字段中。
下一步是将 Query 由可能适用的视图(VIEWS)或规则(RULES)进行修改。这是由 重写(rewrite)系统执行的。
优化器(optimizer)使用 Query 结构来确定 RangeTable 中每个表的最佳表连接顺序和连接类型,使用 Query.jointree(FROM和WHERE子句)来考虑最佳索引使用。
然后,路径(path)模块生成一个最佳的Plan,其中包含执行查询所需的操作。然后,Plan 被传递给执行器(executor)进行执行,并将结果返回给客户端。Plan 实际上是一组节点,以树形结构排列,有一个顶层节点和各种子节点。
还有许多其他模块支持此基本功能。可以通过点击流程图来访问它们。